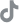多模态数据闭环,如何打造“越用越聪明”的拟人系统?
发布时间:2025-09-22
分享:


几何伙伴数据闭环 2.0 平台打造了一套高效、全面、可扩展的数据驱动体系,正在推动辅助驾驶体验持续革新,不断拓展自研系统产品的智价比边界。
随着辅助驾驶技术逐步走向市场,数据正在成为驱动算法“大脑”不断进化的重要引擎。在辅助驾驶产品开发过程中,如何令海量数据实现价值最大化,在日益复杂的驾驶场景中推动系统性能持续提升?数据闭环的应用,为这一问题提供了高效可行的解决路径。
面向规模化量产需求,几何伙伴推出全新一代数据闭环2.0平台产品,覆盖多模态数据处理与应用的完整流程,通过云平台与全流程自动化技术深度挖掘数据价值,有效提升算法迭代效率,赋能主机厂客户打造“越用越聪明”的辅助驾驶系统产品。
云平台加速数据闭环
要实现真正安全、可靠、泛化能力强的辅助驾驶功能,系统必须能够从真实世界中持续学习迭代,而这一过程离不开数据闭环的支撑。几何伙伴基于云平台打造的数据闭环技术体系,为辅助驾驶系统提供了一套涵盖算法开发、测试验证和量产运营的完整进化链条。
几何伙伴自主建立的多模态数据智算中心,容纳了数个高性能GPU集群,具备PB级分布式存储能力,同时搭载200Gbps的IB网络,可提供PFLOPS级算力。结合一系列私有云平台,几何伙伴数据闭环2.0平台能够有效保障数据传输效率,以及传输和存储过程中的隐私性和安全性,规避数据泄露和滥用的风险,为数据闭环全流程提供统一、安全、灵活的数据湖和云原生基建。
基于这种软硬件深度耦合设计,几何伙伴成功开发出20余条自动化数据产线,覆盖数据采集、数据解析、数据清洗、场景挖掘、云端建图、真值生产、数据回灌、算法测评和仿真测试等环节,为数据飞轮打通了一条畅行无阻的“高速公路”。
为了加速获取高质量数据,几何伙伴数据闭环平台搭载了多种数采及可视化工具,覆盖感知、路测、量产数据等各种数据类型。这套数采系统的设计强调兼容性和多样性,通过制定统一的数据格式和落盘规范,可支持不同车型平台、传感器配置、域控平台和辅助驾驶功能,无缝采集真实驾驶数据、路测数据以及长尾场景数据。同时,在数据制式和数据处理的设计中充分考虑向前兼容,从而实现多项目之间的数据复用。

▲ 几何伙伴车端数据采集业务架构图
在采集/测试数据回传后,数据闭环2.0平台利用自研和开源模型能力,可从静态环境信息、障碍物信息、自车行为、交通参与者行为、交通流信息等多个维度,挖掘出数百万帧算法开发和测试中需要的高价值场景,例如路口、匝道、cut-in、大车、特殊车辆、行人穿行、调头、候车、急刹、极端天气等,充分丰富几何伙伴数据集多样性。
针对不同的算法模型训练需求,平台将对GPU集群进行逻辑池划分和统一调度,并构建多机多卡训练任务模板,高效分配和释放资源,实现训练/推理任务的自动化监控与运维。而在感知和部分开环功能验证阶段,平台也能够结合云端自动化生产的真值数据,从识别能力、识别精度、识别率及稳定性等几个维度进行回灌测评。
依托于数据闭环的全生命周期pipeline,几何伙伴仿真平台可实现实车数据与仿真场景的自动转换,辅以高置信度SIL仿真系统,快速完成基于需求与法规的功能逻辑测试,同时支持云上多节点并发测试。
▲ 几何伙伴数据闭环全链条
同时,在量产运营阶段,这套数据平台也能够基于主机厂客户的具体项目需求,提供完整的量产数据管理服务,包括OBS上传与管理、远程问题分析及回灌复现等,确保运营中的问题及时反馈到算法优化环节中。这种闭环设计,让辅助驾驶系统在用户手中依然能够持续进化,实现真正的拟人学习。
全流程自动化:大模型赋能“智能分拣”
在算法开发流程中,海量高价值数据的获取与应用直接关系到模型训练质量。目前,几何伙伴数据闭环2.0平台每日上云的采集数据量已达10TB,端到端数据可用率达到90%以上,有效场景片段累计超百万clip。而AI大模型的赋能,为数据处理各个环节按下了“加速键”,极大提升了数据的流转效率。
在获取原始采集数据时,几何伙伴的自动化标注系统可通过2D/3D检测与分割,使用现有感知大模型(如针对车辆、行人的模型)对数据进行推理,生成预标注结果。标注员仅需在此基础上进行修正和微调,标注效率较传统逐帧标注的方式提升3-5倍,有效降低数据标注的人力需求。
同时,几何伙伴采用了4D时序自动标注技术,利用SLAM技术和多帧信息(连续图像+点云),自动追踪目标在时空中的运动轨迹。这种标注方式不仅能够精准标注目标的几何属性和语义类别,更能通过连续帧关联捕捉运动状态与交互关系,为感知、预测等提供高精度、低成本的训练数据,是实现动态场景理解的核心基础。
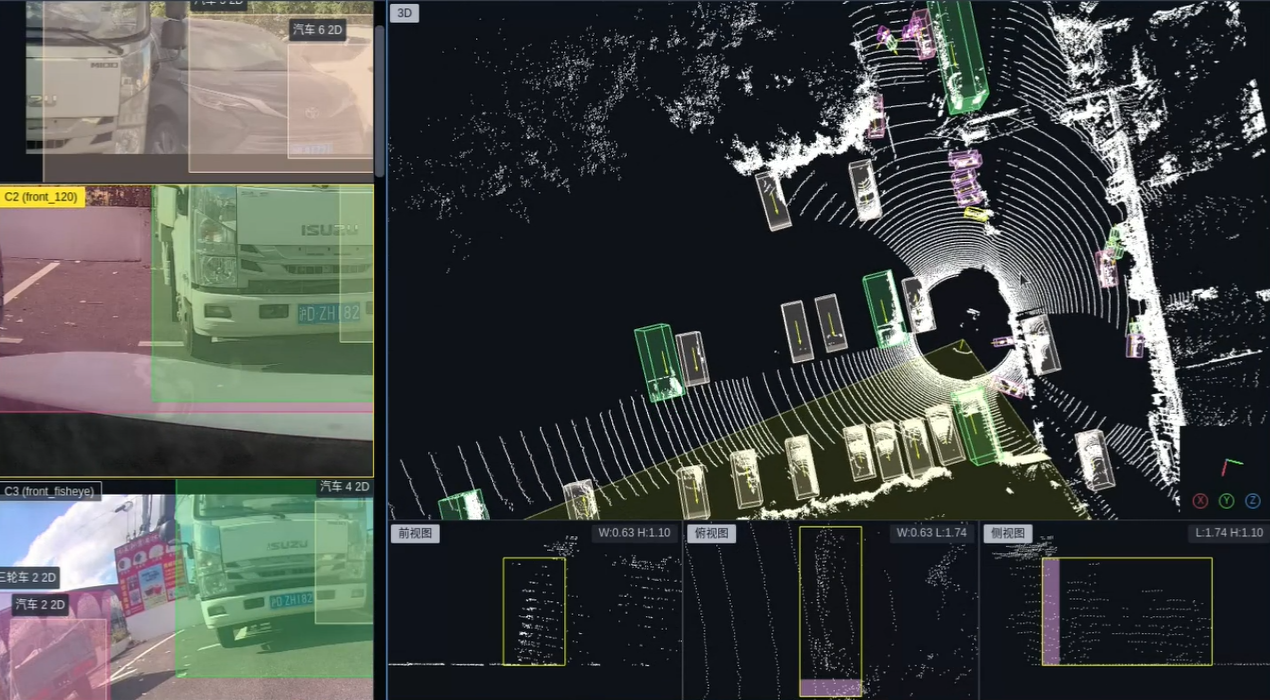
▲ 4D时序标注结果
为高效筛选有价值的数据,几何伙伴的自动标注系统引入了主动学习机制,通过建立智能循环,让模型“主动”分辨需要被标注的数据。具体而言,标注系统将从初始小数据集上训练模型,并对海量未标注数据进行预测、清洗和筛选。在排除预测置信度较低的错误/模糊/冗余数据后,系统将根据特征聚类与影子模式数据对比,智能筛选出最具训练价值的“疑难案例”优先转交人工标注,并以新标注的数据重新训练模型,在此循环中实现数据资源投入产出比的最大化。
借助大模型能力,几何伙伴数据闭环平台可实现以图搜图、以文搜图、以文搜视频片段等功能,帮助进一步优化数据流转效率。在验证端,还可以根据真实路采中挖掘出的关键场景,泛化出成千上万个类似的变异场景,进行充分压力测试。
自动识别相似场景模式,定位稀有事件。当车辆摄像头捕捉到当前道路场景(如:前方有特殊形态的故障车辆、异性道路施工围挡、罕见的静态障碍物)时,可以实时在庞大的Corner Cases数据库中进行检索。
使开发者和管理者能够以人类自然语言与海量的驾驶数据进行交互,极大提升数据利用率和开发迭代速度。同时可以基于模型脆弱性反推漏洞场景,针对性补充数据。
对“以文搜图”能力的时序升级,更适合辅助驾驶动态场景。例如,测试新模型对特殊场景的处理能力时,可以直接输入文字检索指定场景类别,检索出的海量真实视频片段可直接转换为仿真的测试用例,用于对新模型进行自动化、大规模的回归测试,从而确保模型迭代不会出现性能回退。
在具体的部署应用中,几何伙伴数据闭环平台也充分考虑到数据安全需求,引入SSO单点登录、VPN访问控制、RBAC权限管理及多重校验机制,有效规避未经授权的访问与更改,保障数据全生命周期的可追溯性,同时在存储、服务器和网络架构上采用冗余设计,支持数据备份与故障恢复。
写在最后
当前,几何伙伴已经打通原始数据获取→时空对齐→场景重建→多目标追踪→自动化标注→质量验证的4D标注全流程链路,实现日级真值数据生产与小时级测试问题数据分析,可支持算法训练和仿真测试的每周迭代。以云基建能力与全流程自动化为基石,几何伙伴数据闭环 2.0 平台打造了一套高效、全面、可扩展的数据驱动体系,正在推动辅助驾驶体验持续革新,不断拓展自研系统产品的智价比边界。
未来,几何伙伴也将继续以软硬件一体化的全栈能力,为主机厂客户提供更加智能开放的平台化数据服务,共同推动辅助驾驶走向系统级协同进化,构建更加安全可靠的智慧出行新生态。